Web scraping with AgentQL and Playwright

In the age of AI and machine learning data is king. I remember an example in a book I was reading where they compared different algorithms and how sooner or later they would all return the same results given a sufficient amount of data. The argument was being made that instead of investing so much time in making new models we should really focus on curating as much data as we can.
Data, however, can be hard to come by. Sometimes you need data that isn't available via an API or easily exportable, and you need a way to get it; this is where web scraping can come into play. Before I get into my examples below, I have to say, please look at the websites' terms of service and make sure they do not say not to scrape their site. You may see something like, "You may not use automated means, including spiders, robots, crawlers, data mining tools, or the like to download, monitor or use data from this website." This means don't do it, be respectful of the site, and also, it could lead to legal action if the site owner was so inclined to do so. It may also be worthwhile to reach out to the site owners to see if it is okay to scrape the site. When scraping the site, throttle your requests so you are not overloading the servers with traffic they may not be able to handle.
What is web scraping?
Web scraping is simple at its core but can easily become very complex. The definition from the internet is: "Web scraping is the automated process of extracting data from websites using bots or web crawlers. It involves collecting information displayed on web pages and converting it into structured data that can be stored in files or databases for further use."
Let's simplify that a bit. Simply put, you are writing a program to get data from a website by "visiting the site" and parsing the HTML to extract the data that you need. When you extract that data, you want to return it to the end user in a structured format that makes sense to them.
The most common example is that you want price data for products on Amazon. To do this, you would write a scaper to visit Amazon, search for the products, and pull the data from the returned products. Again, this sounds simple. However, Amazon doesn't just return a huge list of products but returns more results as you scroll. This will add more complexity to your scraper. We will cover that later.
A simple scraper
Let's build a simple scraper. First we need to decide what data we need. For this lets go to a site used for training webscraping in this case https://webscraper.io.
Building on the example above with Amazon lets use their simple e-commerce site example https://webscraper.io/test-sites/e-commerce/allinone. This has no pagination or infinite loading on scrolling.
Using AgentQL
One of the most difficult parts of scraping a site is finding the selectors to use in your code to select the write elements. These selectors can change with website updates, breaking your scraper. This is where I find AgentQL to be a great solution and an amazing product. You use simple GraphQL-like queries to find elements with AI on a website. This sounded intimidating to me at first as well, but it's actually so simple it's ridiculous.
Let's start by installing the Chrome extension. This will allow you to test queries live on the site in Chrome without writing any code. You will also need an API key for this so go ahead and set one of those up as well. You can get it here.
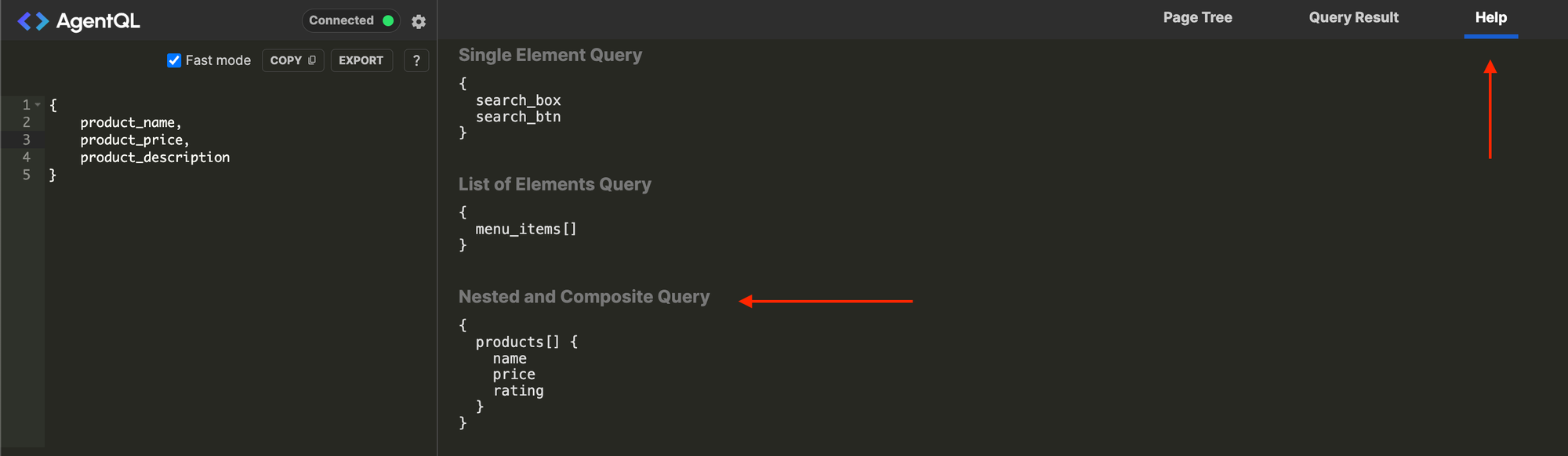
Once you have it installed visit the test e-commerce site and open the Chrome developer tools. You should see an AgentQL tab in your tabs. When you click on it you will see something like the screenshot below. It starts on Help which gives you examples of things to search for. What is great about AgentQL is that it you don't need to know the CSS selectors or XPath for the element you are looking for, just give AgentQL a descriptive idea of what you are looking for. Take a look at the examples keeping in mind the descriptions such as search_btn do not need to match any CSS classes or paths but just a human-readable description of what you are looking for.
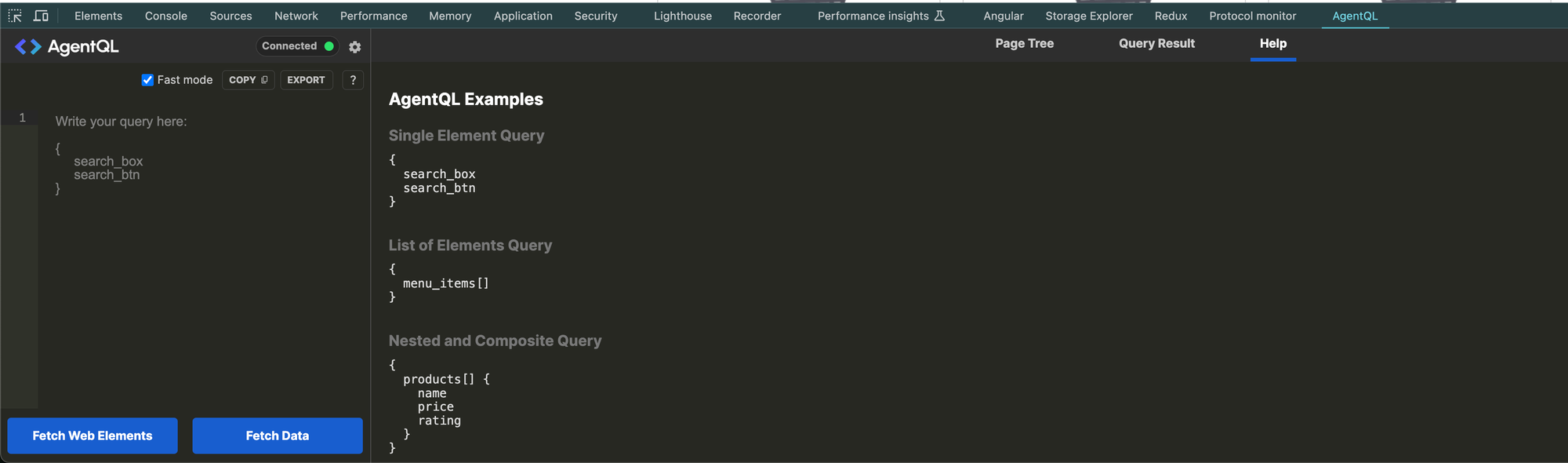
AgentQL in Action
Now, let's move to our example site and see how we can query the names, prices, and descriptions of our products. At the time of writing this, there are three products that look to be laptops: an Acer Aspire for $469.1, an Apple Macbook for $1260.13, and a second Acer Aspire for $485.9. These products will be different for you as they change each time you load the page.
Stating simple lets get the product names. Put the below query in the left-hand query box and click fetch data. Again product_name does not match(at least not intentionally) any selectors in the HTML but just a description of what I wanted to get. You will notice you get the first product name back. We get Acer Aspire ES... because that is what the text of the element is in the HTML. If it were the full text but the ellipsis was being put there by CSS and text-overflow: ellipsis; , it should return the whole thing.
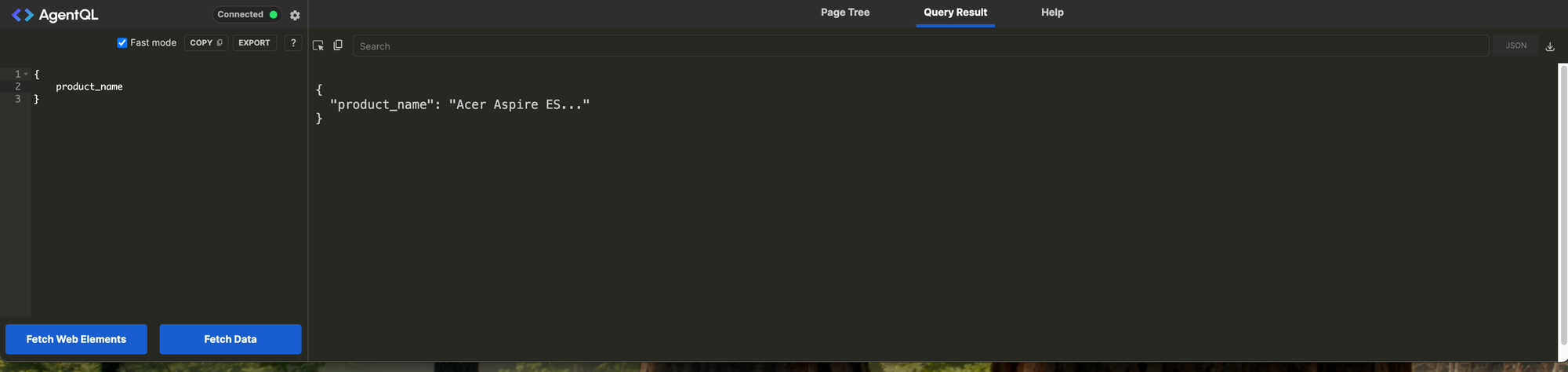
{
product_name
}This is neat, but one product name doesn't do much for us; how do we get all product names? Putting some programming hats on and thinking about what would a list or array of product names look like we could deduce to query with something like product_name[] . Let's try that and see what happens. We now get a JSON-like object back with a key of our selector and a list of product names.
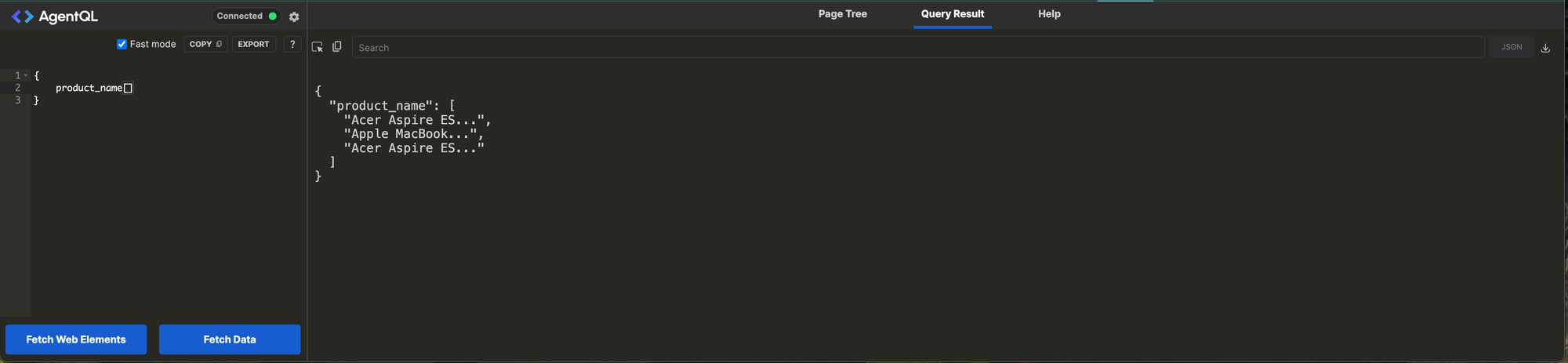
Well, we are getting closer to usable data, but we said we wanted all the data with the name, price, and description for each product. How do we get from here to there? Looking back at our first example but search for something a bit more complex. We know giving something like product_name will give us the name so do we think if we did product_price and product_description we could get those two elements? I bet it works; let's give it a shot.

Now that we know how to get all the product data for a single product let's think back to how we got a list of product names. We gave it a selector product_name and told it we wanted it to be a list by giving it []. However, we don't want to make every selector a list because that would give us three lists, one for each selector as seen in the screenshot below. What we want is known as a Nested and Composite Query. If you go back to the help screen, you will see an example of how to do one of these queries. What this will do is query the page, group each group of elements into its own object and have a list item for each product. Give it a go and see how magical this is.
{
products[] {
product_name,
product_price,
product_description
}
}Nested and Composite query for all products
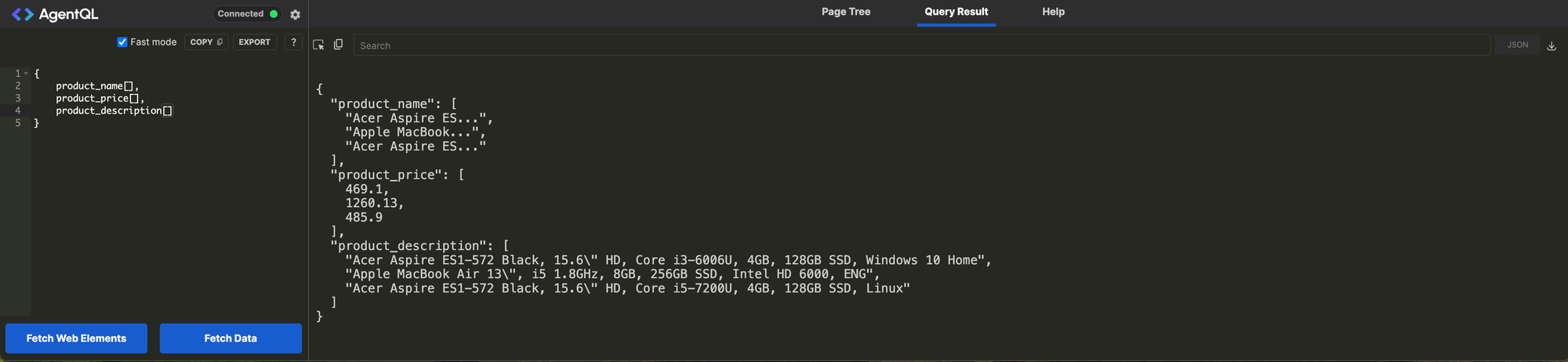
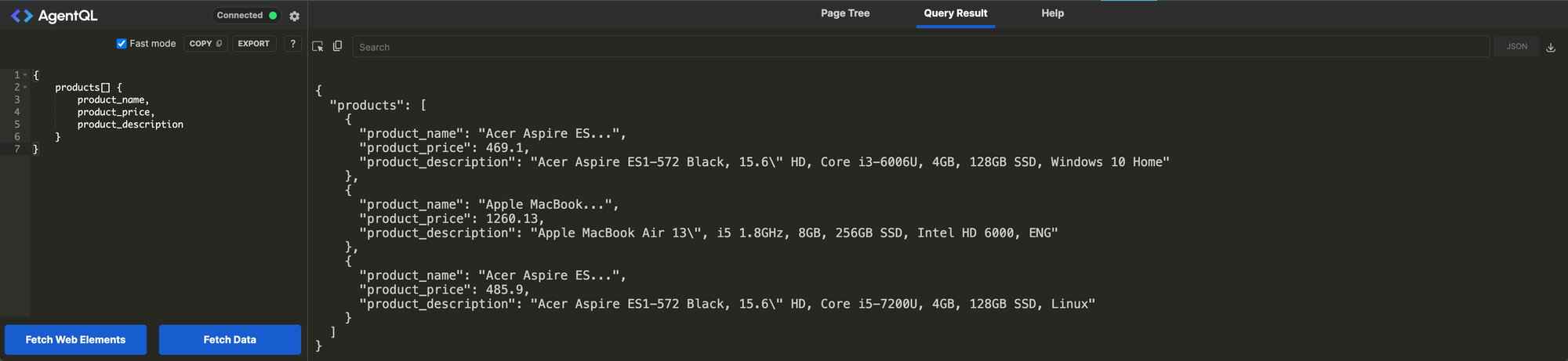
How awesome is that? Not only did you not need to write any code to test your AgentQL, but you can now either export the results as JSON or, if you click the export button right above your query, it will give you a full Python script using Playwright to run this. You will need to install the dependencies to make it work.
Wrapping Up
This was a very simple example of using AgentQL and, in the end, via the Exported Script Playwright and AgentQL to scrape data from a website. I will follow up with another post on handling more complex cases such as logging into a website, handling timeouts, and more complex Javascript. This should, however, get you on your way to scraping data easily with AgentQL.
Helpful Links:
- I made a Github repo for this simple example. It uses a modified version of the export code to save the products to an XLSX file. We go to XLSX instead of CSV because CSV does not support nested data. https://github.com/brandon-braner/agentql_blogpost_example
- AgentQL's Documentation: https://docs.agentql.com/home
- AgentQL's Chrome extension: https://chromewebstore.google.com/detail/agentql-debugger/idnejmodeepdobpinkkgpkeabkabhhej?hl=en
- Python Playwright - Library docs if you want to explore that more. This is a better example of how to use it not in context of righting tests: https://playwright.dev/python/docs/library



