Setting Up a Powerful PostgreSQL Environment for AI and LLM's: Installing TimescaleDB, pgvector, and pgAI

In this blog post, we'll walk through the process of setting up a robust PostgreSQL environment on a Linux server. We'll cover the installation of PostgreSQL, TimescaleDB, pgvector, and pgAI. This combination provides a powerful database setup capable of handling time-series data, vector operations, and AI-powered functionality.
Why TimescaleDB and pgvector instead of Pinecone?
Before we dive into the installation process, let's discuss why you might choose TimescaleDB with pgvector over alternatives like Pinecone.
TimescaleDB: Time-Series Superpowers
1. Seamless PostgreSQL Integration: TimescaleDB is an extension of PostgreSQL, allowing you to leverage the full power of PostgreSQL while gaining specialized time-series capabilities.
2. Scalability: TimescaleDB is designed to handle large volumes of time-series data efficiently, with features like automatic partitioning and query optimization.
3. SQL Interface: Unlike some specialized time-series databases, TimescaleDB uses standard SQL, making it easier for teams already familiar with PostgreSQL.
4. Continuous Aggregates: TimescaleDB offers automatic, real-time aggregations of time-series data, reducing query times for common analytical operations.
pgvector: Versatile Vector Operations
1. Integrated Vector Search: pgvector adds vector similarity search capabilities directly to PostgreSQL, allowing you to perform vector operations alongside traditional relational data.
2. Cost-Effective: As part of your PostgreSQL database, pgvector doesn't require a separate service or additional infrastructure, potentially reducing costs.
3. Flexibility: You can combine vector searches with standard SQL queries, enabling complex operations that blend structured and unstructured data.
Comparison with Pinecone
While Pinecone is a powerful, purpose-built vector database, the combination of TimescaleDB and pgvector offers some unique advantages:
1. All-in-One Solution: With TimescaleDB and pgvector, you get time-series capabilities, vector operations, and traditional relational database features in a single system. Pinecone focuses solely on vector operations.
2. Data Consistency: Keeping your vector data alongside your relational data ensures consistency and simplifies transactions.
3. Cost Control: As part of your PostgreSQL setup, you have more control over infrastructure costs compared to a separate managed service.
4. Learning Curve: If your team is already familiar with PostgreSQL, the learning curve for TimescaleDB and pgvector will be gentler than adopting a completely new system.
5. Customization: Being open-source and part of the PostgreSQL ecosystem, TimescaleDB and pgvector offer more opportunities for customization and integration with other tools.
However, it's worth noting that Pinecone may offer advantages in certain scenarios:
• If you need a fully managed, specialized vector database service.
• For extremely large-scale vector search operations where Pinecone's distributed architecture might outperform.
• When you don't need the additional features of a full relational database or time-series capabilities.
Ultimately, the choice between TimescaleDB with pgvector and alternatives like Pinecone depends on your specific use case, existing infrastructure, and team expertise. The setup we're about to walk through provides a versatile, powerful, and cost-effective solution for many scenarios requiring both time-series and vector capabilities.
1. Installing PostgreSQL and TimescaleDB
First, let's install PostgreSQL and TimescaleDB. TimescaleDB is an extension to PostgreSQL for time-series data.
# Update package list
sudo apt update
# Install necessary packages
sudo apt install gnupg postgresql-common apt-transport-https lsb-release wget
# Add PostgreSQL repository
sudo /usr/share/postgresql-common/pgdg/apt.postgresql.org.sh
# Add TimescaleDB repository
echo "deb https://packagecloud.io/timescale/timescaledb/ubuntu/ $(lsb_release -c -s) main" | sudo tee /etc/apt/sources.list.d/timescaledb.list
# Add TimescaleDB GPG key
wget --quiet -O - https://packagecloud.io/timescale/timescaledb/gpgkey | sudo gpg --dearmor -o /etc/apt/trusted.gpg.d/timescaledb.gpg
# Update package list again
sudo apt update
# Install TimescaleDB and PostgreSQL client
sudo apt install timescaledb-2-postgresql-16 postgresql-client-16
# Optimize PostgreSQL configuration for TimescaleDB
sudo timescaledb-tune
# Restart PostgreSQL service
sudo systemctl restart postgresql
2. Configuring PostgreSQL
Now, let's configure PostgreSQL for remote access and set up a password for the postgres user.
# Access PostgreSQL prompt
sudo -u postgres psql
# Set password for postgres user
\password postgres
# Exit PostgreSQL prompt
\q
# Next, we need to modify PostgreSQL configuration files to allow connections from any IP:
# Edit postgresql.conf
sudo vim /etc/postgresql/16/main/postgresql.conf
# Find and modify the listen_addresses line:
# listen_addresses = '*'
# Edit pg_hba.conf
sudo vim /etc/postgresql/16/main/pg_hba.conf
# Add the following line at the end of the file:
# host all all 0.0.0.0/0 md5
# Restart PostgreSQL to apply changes
sudo systemctl restart postgresql3. Adding TimescaleDB Extension
Let's add the TimescaleDB extension to our PostgreSQL database:
sudo -u postgres psql
# Create TimescaleDB extension
CREATE EXTENSION IF NOT EXISTS timescaledb;
# Exit PostgreSQL prompt
\q4. Installing pgvector and pgAI
Now, we'll install pgvector for vector operations and pgAI for AI-powered database functions.
# Install required packages
sudo apt install postgresql-16-vector postgresql-plpython3-16 python3-pip
# Access PostgreSQL prompt
sudo -u postgres psql
# Create pgvector extension
CREATE EXTENSION vector;
# Create Python extension
CREATE EXTENSION plpython3u;
# Exit PostgreSQL prompt
\q
# Clone pgAI repository
git clone https://github.com/timescale/pgai.git
# Install pgAI
cd pgai
sudo make installSetting Up Cloudflare Tunnel (Optional)
If you want to set up a Cloudflare Tunnel for secure access to your database, you can do so at this point.
Cloudflare Tunnel provides a secure way to connect your PostgreSQL server to Cloudflare's network without exposing it directly to the internet. This adds an extra layer of security and eliminates the need to open inbound ports on your firewall. Here's how to set it up:
1. Install cloudflared
First, you need to install the cloudflared daemon on your server:
# Download the latest cloudflared package
wget -q https://github.com/cloudflare/cloudflared/releases/latest/download/cloudflared-linux-amd64.deb
# Install the package
sudo dpkg -i cloudflared-linux-amd64.deb
# Check the installation
cloudflared version2. Authenticate cloudflared
You need to authenticate cloudflared with your Cloudflare account:
cloudflared tunnel loginThis command will provide a URL. Open this URL in your browser, log in to your Cloudflare account, and select the domain you want to use for your tunnel.
3. Create a Tunnel
Now, create a new tunnel:
cloudflared tunnel create postgresql-tunnelThis will create a new tunnel and generate a credentials file.
4. Configure the Tunnel
Create a configuration file for your tunnel:
sudo vim ~/.cloudflared/config.ymlAdd the following content, replacing YOUR_TUNNEL_ID with the ID of the tunnel you just created:
tunnel: YOUR_TUNNEL_ID
credentials-file: /root/.cloudflared/YOUR_TUNNEL_ID.json
ingress:
- hostname: db.yourdomain.com
service: tcp://localhost:5432
- service: http_status:404This configuration will route traffic from db.yourdomain.com to your local PostgreSQL server.
5. Create a DNS Record
Create a DNS record to route traffic to your tunnel:
cloudflared tunnel route dns postgresql-tunnel db.yourdomain.com6. Start the Tunnel
Now, start your tunnel:
cloudflared tunnel route dns postgresql-tunnel db.yourdomain.comsudo systemctl start cloudflared
This will install cloudflared as a system service and start it.
Since we already updated our postgres conf above, we should now be able to connect to our database using our domain.
8. Connect to Your Database
Now you can connect to your database using the Cloudflare Tunnel. Use db.yourdomain.com as the hostname, and PostgreSQL's default port (5432).
For example, using psql:
psql -h db.yourdomain.com -U your_username -d your_databaseSecurity Considerations
1. Access Control: Even though your database is now accessible via Cloudflare, make sure to use strong passwords and limit user permissions appropriately.
2. SSL/TLS: Consider enabling SSL/TLS on your PostgreSQL server for encrypted connections.
3. Firewall: Configure your server's firewall to only allow inbound connections from Cloudflare's IP ranges.
4. Monitoring: Regularly monitor your tunnel and database logs for any suspicious activity.
By using a Cloudflare Tunnel, you've added an extra layer of security to your PostgreSQL setup. Your database is not directly exposed to the internet, reducing the attack surface and providing a secure method of remote access.
Configuring Ollama (Optional)
If you're using Ollama with your setup for pg admin, you can set the allowed origins:
export OLLAMA_ORIGINS="http://ollama.yourdomain.tld"Using Docker
Don't want to setup Timescale and pgvector manually and just want to use Docker? Follow the instructions below. Instructions on Timescales website here. However, they do not cover enabling the extensions pgvector and pgai see below for those instructions.
1. Pull the image
docker pull timescale/timescaledb-ha:pg16- Run the image
Run the following to run the docker image. Please update POSTGRES_PASSWORD=password with your own password.
docker run -d --name timescaledb -p 5432:5432 -e POSTGRES_PASSWORD=password timescale/timescaledb-ha:pg16
- Connect to the database and create the extensions.
While the image comes with the pgvector, plpython and pgai extensions installed the are not created in the database, run the following sql to enable them.
CREATE EXTENSION vector;
CREATE EXTENSION plpython3u;
CREATE EXTENSION ai;
# run this to verify they are installed
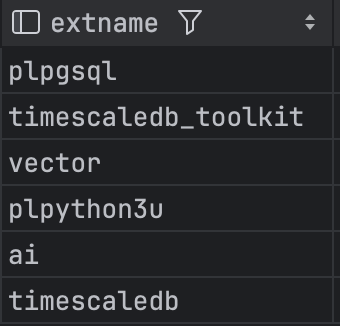
SELECT extname FROM pg_extension;You should now see the following extensions.
Conclusion
I hope this helps you on your journey to using Postgres as your vector database and enjoying everything that Timescale offers in terms of scalability.
Be sure to check back as I write more posts about utilizing pgai to generate your embeddings when working with your Postgres data vs using an external pipeline.



